문자 인코딩
컴퓨터의 언어
개발하면서 우리는 우리의 언어(자연어)를 사용한다. 예를 들면
1
String introduce = "안녕하세요. Leoh 입니다."
처럼 말이다. 이런 자바 코드를 보고 컴퓨터는 어떻게 해석할까? 컴퓨터가 한글과 영어를 잘 아는 저명한 통역가일까?
사실 그렇지 않다. 컴퓨터는 0과 1밖에 모른다. “트랜지스터” 라고 불리는 스위치가 켜지고(1) 꺼지는(0) 것으로만 작동한다. 어떻게 그럴 수 있을까? 바로 이진법 덕분(?)이다.
이진법을 사용하면 0과 1로 많은 정보를 표현할 수 있다. 간단하게 정수로 예를 들면, 0은 0이고, 1은 1이다. 당연하다. 그렇다면 3은 어떻게 표현할까? 이 스위치가 두 개 있으면 된다. 11. 왼쪽에 있는 1은 사실 2이다. 이게 대체 무슨 말이냐면, 왼쪽에 1이 붙을 때마다 그 1은 2의 n승이 된다.
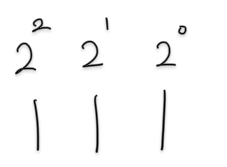
11이면, 21(2) + 20(1) 이기 때문에 3이다. 111이면, 22(4) + 21(2) + 20(1) 이므로 7이다.
이런 방법으로 컴퓨터는 다양한 숫자를 표시할 수 있다. 그런데 우리가 궁금한 것은 숫자가 아니라 문자이다. 0과 1밖에 모르는 컴퓨터는 문자를 어떻게 사용할까?
문자집합 (Character Set)
컴퓨터는 여러개의 0과 1을 사용해서 많은 수를 표현할 수 있다. 그래서 고안 해낸 것이 바로 문자집합 (CharacterSet)이다.
컴퓨터가 알 수 있는 0, 1로 만들어진 숫자를 문자로 변환하는 것이 디코딩(Decoding)이고, 문자를 숫자로 변환하는 것이 인코딩(Encoding) 이다. 이 부분이 좀 헷갈리는데, 사람이 읽을 수 있는 문자를 컴퓨터가 읽을 수 있는 코드로 변환(부호화)한다고 생각하면 된다.
ASCII (American Standard Code for Information Interchange, 1963)
컴퓨터가 처음 등장할 때, 고안된 영어 기반 문자집합 표준이다. 7bit만을 사용하는 문자 집합이다. 즉 27 인 128개의 숫자를 나타낼 수 있다.
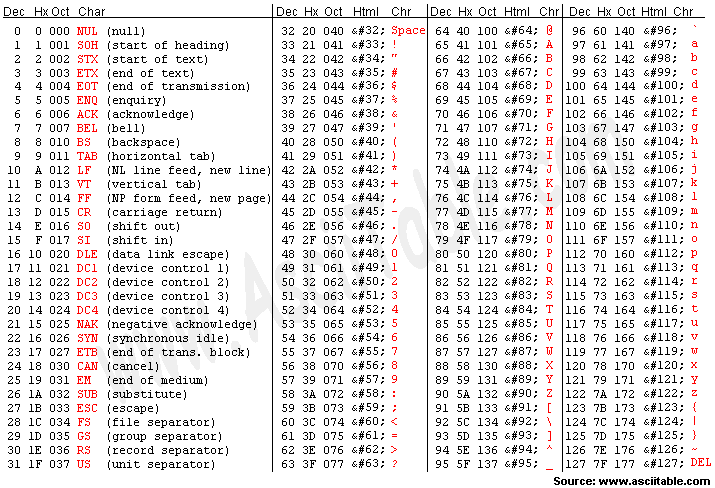
실제 ASCII 코드 표를 살펴보자. 7bit 만을 사용하기 때문에 0~127번 까지 총 128개의 문자표가 있다. 기능, 특수문자, 영어알파벳 등이 128개의 숫자 안에 매핑되어있다. 숫자 65를 ASCII로 변환하면 ‘A’이다. 소문자는 97부터 ‘a’가 시작하므로, ‘a’ - 32 = ‘A’인 셈이다.
ASCII의 문제점이 무엇인 지 혹시 알겠는가? 바로 문자 개수의 한계이다. 애초에 영어만을 기준으로 만들어졌기 때문에 다른 문자는 ASCII 코드로 표현할 수가 없다.
ISO 8859-1 (Latin-1, 1980..)
ASCII 코드는 영어 알파벳만을 지원했기 때문에 서유럽 문자 등을 표현할 수 없었다. 서유럽 문자는 Ã 이런 식으로 생긴 알파벳이다. 0 ~ 127까지 27 은 ASCII를 그대로 유지하고, 1bit를 추가하여 128개의 문자를 추가하였다. 1byte(=8bit)를 사용하며, 총 256가지 문자를 사용할 수 있다.
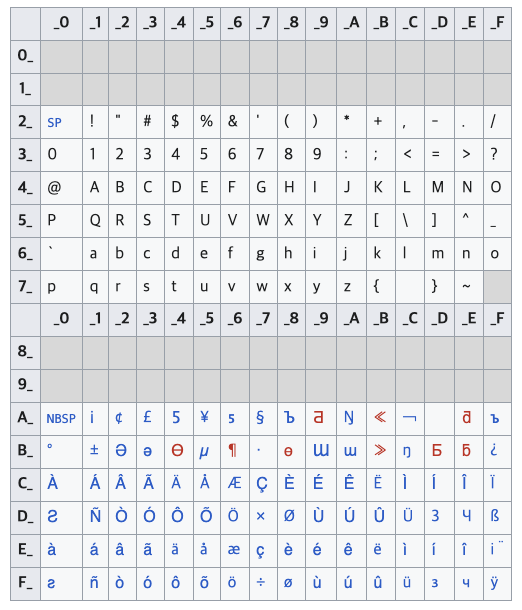
ASCII의 문자표는 그대로 사용하기 때문에, ASCII와 호환된다. 즉, ISO 8859-1 로 인코딩된 문자 중 ASCII 문자집합에 포함되는 0~127 의 문자는 정상적으로 디코딩할 수 있다.
한글 문자 집합
우리는 한국인이다. 지금 내가 쓰고 있는 글도 ASCII와 ISO 8859-1은 인식하지 못한다. 따라서 한글을 지원해주는 다른 문자집합이 필요하다.
EUC-KR
한글은 초성,중성,종성 세 개의 문자로 매우 많은 글자를 만들 수 있기 때문에 굉장히 거대한 문자집합이 필요하다. EUC-KR은 초창기에 등장한 한글 지원 문자 집합이다. 자주 사용하는 한글 2,350개를 포함해서 만들었다.
그런데, 한글은 매우 많기 때문에 1byte인 256개로 나타낼 수가 없다. 가, 갸, 각, 갂, 갹, 갺, 겪, 걲…. 끝이 없다. 따라서 한글은 2byte(16bit)를 사용해야 한다. 2byte는 216 이며 65,536 가지가 표현 가능하다.
EUC-KR은 기존의 ASCII(0~127)를 포함하며 거기에 자주 사용하는 한글 2,350개 + 자주 사용하는 기타 글자 + 한자 + 일본어 등을 포함하는 문자 집합이다. ASCII를 사용할 때에는 1Byte만 사용되고, 한글은 2Byte를 사용한다. 하지만, 주로 사용하는 문자만 포함하고 있기 때문에, 주로 사용하지 않는 뷁 같은 복잡한 문자는 인식하지 못한다.
MS-949
마이크로 소프트에서 EUC-KR을 확장하여 만든 문자집합이다. 한글은 초성, 종성, 종성을 모두 조합하면 11,172자가 나오는데, MS-949에서는 이를 모두 사용할 수 있다. EUC-KR을 확장했기 때문에 ASCII 역시 호환되고, EUC-KR과 마찬가지고 ASCII는 1Byte, 한글은 2Byte를 사용한다.
한글버전 윈도우에서는 기본적으로 이 인코딩 방법을 사용하기 때문에, OS 간에 문자를 주고받거나 파일 작성등을 할 때 종종 문제가 생기기도 한다. 내가 경험 상 STS 같은 IDE도 기본 인코딩 설정이 MS-949여서 애 먹었던 기억이 있다.
유니코드(Unicode)
전 세계적으로 컴퓨터 사용량이 증가하면서 모든 문자를 사용할 수 있는 표준 문자집합 같은 것이 필요했다. 그렇게 탄생한 것이 유니코드이다. 유니코드에는 2가지 매핑 방식이 있는데, 유니코드 변환 형식(Unicode Transformation Format, UTF) 인코딩, 국제 문자 세트(Universal Coded Character Set, UCS) 인코딩 이다.
우리가 알아볼 것은 바로 UTF 이다.
UTF-16
유니코드 초창기에는 UTF-16이 인기를 끌었다. 모든 글자를 2Byte만으로 표현할 수 있기 때문에 편리하고 좋았다. 자바 역시 내부적으로는 UTF-16을 사용하여 인코딩한다.
때문에, 자바에서 char가 2Byte이다. 영문이라도 2Byte로 인식한다. 이는 비효율적이므로 자바는 영문만 존재하는 String인 경우 char가 아닌 byte를 사용하여 최적화를 한다.
하지만, 대부분의 문서는 영어로 되어있고 영어는 원래 ASCII로 하면 1Byte이다. UTF-16으로 인코딩하면 굳이 한 글자에 2Byte씩 사용해야 한다. 즉, ASCII와 호환이 안 된다. 이 부분은 굉장한 단점이 될 수 있다. 수 많은 레거시 들은 ASCII로 인코딩 되어있기 때문이다.
UTF-8
최근에는 거의 표준처럼 사용하는 UTF-8 이다. UTF-8은 1Byte(8bit) 기반의 가변길이 인코딩이다. ASCII, 영문, 라틴문자등은 기존(ASCII, ISO-8869)처럼 1Byte만을 사용한다. 그리스어, 히브리어 등은 2Byte를 사용하고, 한글 한자 일본어는 3byte, 이모지, 고대문자 등은 4byte를 사용한다.
길이가 가변적인 만큼 상대적으로 사용이 복잡하지만 ASCII를 1byte로 표현하고, ASCII를 호환할 수 있기 떄문에 사실상 현대 인코딩의 표준이라고 볼 수 있다.
호환
지금까지의 알아 본 문자 집합 사이의 호환성을 정리해보자.
- ASCII로 인코딩된 숫자를 디코딩할 수 있는 문자 집합이 뭘까?
- ISO 8859-1: 일부 가능(0~127만)
- EUC-KR: 가능
- MS-949: 가능
- UTF-16: 불가능
- UTF-8: 가능
- 한글 문자 ‘가’를 인코딩 할 수 있는 문자 집합이 뭘까?
- ASCII: 불가능
- ISO 8859-1: 불가능
- EUC-KR: 가능 (2byte)
- MS-949: 가능 (2byte)
- UTF-16: 가능 (2byte)
- UTF-8: 가능 (3byte)
- 복잡한 한글 문자 ‘뷁’을 디코딩할 수 있는 문자 집합이 뭘까?
- ASCII: 불가능
- ISO 8859-1: 불가능
- EUC-KR: 불가능
- MS-949: 가능 (2byte)
- UTF-16: 가능 (2byte)
- UTF-8: 가능 (3byte)
마지막으로 알아야할 점들을 정리해보자.
MS-949는EUC-KR을 확장한 인코딩이다. 따라서EUC-KR로 인코딩한 한글 문자는MS-949로 디코딩 가능하다.- 반대로,
MS-949는EUC-KR에 없는 한글 문자(ex. 뷁)를 포함한다. 이런 문자는EUC-KR로는 디코딩이 불가능하다. UTF-16혹은UTF-8은EUC-KR과 관련이 없다. 아예 다른 문자 집합이기 때문에EUC-KR, 그리고 그 확장인MS-949로 인코딩된 한글 문자는UTF로 디코딩할 수 없다.- 하지만
EUC-KR,MS-949,UTF-8은 ASCII 를 지원하기 떄문에, 영어 문자는 서로 디코딩할 수 있다. 단,UTF-16은 ASCII를 지원하지 않기 때문에 디코딩할 수 없다.Reference
- https://ko.wikipedia.org/wiki/%EC%9C%A0%EB%8B%88%EC%BD%94%EB%93%9C
- 김영한의 실전 자바 고급2 강의